주석에 부족한 내용이 있으면 물어보세요
CNN은 Convolution과 Pooling을 반복적으로 사용하면서 불변하는 특징을 찾고, 그 특징을 입력데이터로 신경망에 보내 Classification을 수행합니다.
- Convolution Layer : 필터를 통해 이미지의 특징을 추출.
- Pooling Layer : 특징을 강화시키고 이미지의 크기를 줄임
Padding은 Convolution을 수행하기 전, 입력 데이터 주변을 특정 픽셀 값으로 채워 늘리는 것입니다.
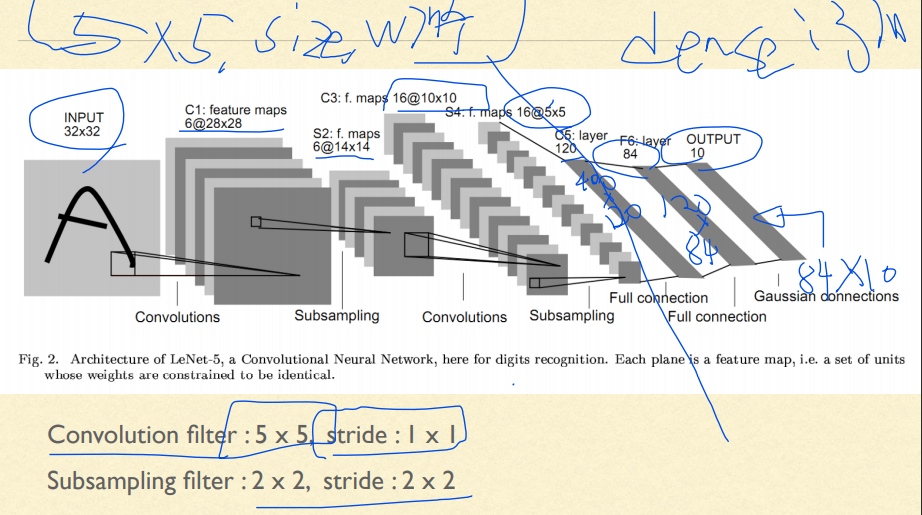
# Day_21_01_CNNFirst.py
import tensorflow.compat.v1 as tf
tf.disable_eager_execution()
# compat 때문에 써줘야함 <- 낮은 버전 쓸것임
import numpy as np
# 시계열 데이터는 2치원 이미지는 3차원 (WHD)
# -> 이말은 3차원을 여러개 사용하는것 즉 4차원을 다루는 것이다. ( 3차원이 제일 어렵다. why? 2차원을 바꿔야함)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
print(x_train.shape, x_test.shape) # (60000, 28, 28) (10000, 28, 28)
print(y_train.shape, y_test.shape) # (60000,) (10000,)
print(x_train.dtype, y_train.dtype) # uint8 uint8
# x_train = np.float32(x_train)
# x_test = np.float32(x_test)
# 이렇게 스케일링 해주면 훨씬 괜잖을 것
x_train = x_train / 255
x_test = x_test / 255
# 4차원으로 변환
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
# ------------------------------------------------ #
# filter 는 똑같이 4차원 즉 w = 4차원
w1 = tf.Variable(tf.random.normal([3, 3, 1, 32])) # 클래스 개념 존재 마지막 32
# 바이어스
b1 = tf.Variable(tf.zeros([32]))
print(w1.shape)
# 필터는 3, 3, 32 // 32의 이유 앞에서 3,3,1 짜리 필터를 32개 만들었으니 깊이는 32가 되는 것임
w2 = tf.Variable(tf.random.normal([3, 3, 32, 64]))
b2 = tf.Variable(tf.zeros([64]))
# dense layer
# 밑에 계산한 p2.shape 따라감
w3 = tf.Variable(tf.random.normal([7 * 7 * 64, 128])) # 뒤의 숫자는 자유임
b3 = tf.Variable(tf.zeros([128]))
w4 = tf.Variable(tf.random.normal([128, 10])) # 뒤의 숫자는 자유임
b4 = tf.Variable(tf.zeros([10]))
# ------------------------------------------------ #
# 인풋을 정해주는 것임 -> 중간중간의 shape 추적하기 위해
ph_x = tf.placeholder(tf.float32, shape=[None, 28, 28, 1]) # x_train 형식
ph_y = tf.placeholder(tf.int32)
c1 = tf.nn.conv2d(ph_x, # 행렬 곱셈이라고 생각하면 편함
filter=w1,
strides=[1, 1, 1, 1], # 가온데 2개만 사용하고 앞(배치 size) 뒤(채널)는 사용 안함, 한번에 얼만큼 움직이는지
padding='SAME') # 파라미터의 수를 줄여나가는 과정 = padding -> 차원의 크기 유지시켜줌
# # same : 필터의 사이즈가 k이면 사방으로 k/2 만큼의 패딩을 준다.
r1 = tf.nn.relu(c1 + b1) # 코드가 선명해짐
# 풀링 ( 입력, 커널[ ,커널의 크기 2*2,], strides, padding) 채널의 크기 바뀌지 않음 'SAME'을 사용해서
p1 = tf.nn.max_pool2d(r1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 앞쪽의 출력이 뒤쪽이랑 연결시킴
c2 = tf.nn.conv2d(p1, filter=w2, strides=[1, 1, 1, 1], padding='SAME')
r2 = tf.nn.relu(c2 + b2)
p2 = tf.nn.max_pool2d(r2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
print(c1.shape, p1.shape) # (60000, 28, 28, 32) (60000, 14, 14, 32)
print(c2.shape, p2.shape) # (60000, 14, 14, 64) (60000, 7, 7, 64)
# p2 = 4차원 -> 3차원으로 바꿔줘야함
flat = tf.reshape(p2, shape=[-1, p2.shape[1] * p2.shape[2] * p2.shape[3]])
print(flat.shape) # (60000, 3136)
# (60000, 128) = (60000, 3136) @ (3136, 128)
d3 = tf.matmul(flat, w3) + b3
r3 = tf.nn.relu(d3)
# 10개의 숫자중 가장 높은 확률인 것을 출력하는 것임
# (60000, 10) = (60000, 128) @ (128, 10)
z = tf.matmul(r3, w4) + b4
hx = tf.nn.softmax(z)
# ------------------------------------------------ # 13_02에서 가져옴
loss_i = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=z, labels=ph_y)
loss = tf.reduce_mean(loss_i)
# ------ #
optimizer = tf.compat.v1.train.AdamOptimizer(0.001)
train = optimizer.minimize(loss)
sess = tf.compat.v1.Session()
sess.run(tf.compat.v1.global_variables_initializer())
# 미니 배취 소스 수정
epochs = 10 # 전체 데이터 셋을 몇번이나 사용할 것인지
batch_size = 100 # 한번에 몇개 가져와 사용 할 것인지
n_iteration = len(x_train) // batch_size # 몇번 반복을 해야하는지 정수 나눗셈
# 기술이 들어감
for i in range(epochs):
total = 0
for j in range(n_iteration): # 전체 반복 6천번
n1 = j * batch_size # 0 100 200 300
n2 = n1 + batch_size # 100 200 300 400
xx = x_train[n1:n2]
yy = y_train[n1:n2]
sess.run(train, {ph_x: xx, ph_y: yy}) # weight 업데이트
total += sess.run(loss, {ph_x: xx, ph_y: yy})
print(i, total / n_iteration)
print('-' * 30)
preds = sess.run(hx, {ph_x: x_test})
print(preds.shape)
preds_arg = np.argmax(preds, axis=1)
print('acc :', np.mean(preds_arg == y_test))
sess.close()
# ------------------------------------------------ #
# 0 100268.926428833
# 1 18584.445092716218
# 2 10545.577516269685
# 3 6856.872360249708
# 4 4815.226146472693
# 5 3506.253878757159
# 6 2582.4858995021877
# 7 1973.0029461661975
# 8 1548.0812740890185
# 9 1184.6632283165056
# (10000, 10)
# acc : 0.968
# 하이퍼 파라미터 고쳐보기
'인공지능 > CNN' 카테고리의 다른 글
| 이미지 증식 (0) | 2020.12.09 |
|---|---|
| 이미지 사이즈 조절 및 이미지 분석 (feat. VGG) (0) | 2020.12.04 |
| VGG (0) | 2020.12.04 |
| LeNet5 (0) | 2020.12.04 |
| #2 (#1에서 했던) CNN 코드 Keras 사용해보기 (0) | 2020.12.01 |